This is the class of objects denoting (monoid) homomorphisms. Such an expression means to iterate through a collection, applying a function to each element, accumulating the results along the way with an operation, and returning the end result. More precisely, it is the built-in version of the general computation scheme whose instance is the following ``hom'' functional, which may be formulated recursively, for the case of a list collection, as:
Clearly, this scheme extends a function f to a homomorphism of monoids, from the monoid of lists to the monoid defined by &lang#langle;&oplus#oplus;,(&oplus#oplus;)&rang#rangle;.
Thus, an object of this class denotes the result of applying such a homomorphic
extension of a function (f) to an element of collection monoid
(i.e., a data structure such as a set, a list, or a bag), the image
monoid being implicitly defined by the binary operation (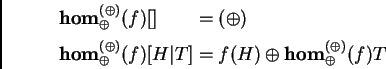 )--also
called the accumulation operation. It is made to work iteratively.
)--also
called the accumulation operation. It is made to work iteratively.
For technical reasons, we need to treat specially so-called collection homomorphisms; i.e., those whose accumulation operation constructs a collection, such as a set. Although a collection homomorphism can conceptualy be expressed with the general scheme, the function applied to an element of the collection will return a collection (i.e., a free monoid) element, and the result of the homomorphism is then the result of tallying the partial collections coming from applying the function to each element into a final ``concatenation.''
Other (non-collection) homomorphisms are called primitive homomorphisms. For those, the function applied to all elements of the collection will return a computed element that may be directly composed with the other results. Thus, the difference between the two kinds of (collection or primitive) homomorphisms will appear in the typing and the code generated (collection homomorphism requiring an extra loop for tallying partial results into the final collection). It is easy to make the distinction between the two kinds of homomorphisms thanks to the type of the accumulation operation (see below).
Therefore, a collection homomorphism expression constructing a collection of type c2(B) consists of:
A primitive homomorphism computing a value of type B consists of:
Even though the scheme of computation for homomorphisms described above is correct, it is not often used, especially when the function already encapsulates the accumulation operation, as is always the case when the homomorphism comes from the desugaring of a comprehension--see below). Then, such a homomorphism will directly side-effect the structure specified as the identity element with a function of the form lambda(x) op(x,id) and dispense altogether with the need to accumulate intermediate results. We shall call those homomorphisms in-place homomorphisms. To distinguish them and enable the suprression of intermediate computations, a flag indicating that the homomorphism is to be computed in-place is provided. Both primitive and collection homomorphisms can be specified to be in-place. If nothing regarding in-place computation is specified for a homomorphism, the default behavior will depend on whether the homomorphism is collection (default is in-place), or primitive (default is not in-place). Methods to override the defaults are provided.
For an in-place homomorphism, the iterated function encapsulates the operation, which affects the identity element, which thus accumulates intermediate results and no further composition using the operation is needed. This is especially handy for collections that are often represented, for (space and time) efficiency reasons, by iteratable bulk structures constructed by allocating an empty structure that is filled in-place with elements using a built-in ``add'' method guaranteeing that the resulting data structure is canonical - i.e., that it abides by the algebraic properties of its type of collection (e.g., adding an element to a set will not create duplicates, etc.).
Although monoid homomorphisms are defined as expressions in the kernel, they are not meant to be represented directly in a surface syntax (although they could, but would lead to rather cumbersome and not very legible expressions). Rather, they are meant to be used for expressing higher-level expressions known as monoid comprehensions, which offer the advantage of the familar (set) comprehension notation used in mathematics, and can be translated into monoid homomorphisms to be type-checked and evaluated.
A monoid comprehension is an expression of the form:
[op,id] { e | q_1, ..., q_n }
where [op,id] define a monoid, e is an expression, and the
q_i's are qualifiers. A qualifier is either a
boolean expression or a pair x <- e, where x is
a variable and e is an expression. The sequence of qualifiers may
also be empty. Such a monoid comprehension is just syntactic sugar that
can be expressed in terms of homomorphisms as follows:
[op,id]{e | } = op(e,id);
[op,id]{e | x <- e', Q} = hom(e',lambda> x.[op,id]{e | Q}, op, id);
[op,id]{e | c, Q} = if c then [op,id]{e | Q} else id;
This is explained more formally in Section 3.28.
Comprehensions are also interesting as they may be subject to transformations leading to more efficient evaluation than their simple ``nested loops'' operational semantics (by using ``unnesting'' techniques and using relational operations as implementation instructions). At any rate, homomorphisms are here treated ``naively'' and compiled as simple loops.